Contenido
- ¿Qué es la idempotencia?
- ¿Por qué los reintentos son inevitables?
- Operaciones que ya son idempotentes
- ¿Cómo se implementa en la práctica?
- Usos comunes en IT
- Beneficios de implementarla
- Detalles que importan en producción
- Conclusión
¿Qué es la idempotencia?
La definición de idempotencia dice que es la propiedad para realizar una acción determinada varias veces y aun así conseguir el mismo resultado que se obtendría si se realizase una sola vez. Hay un ejemplo de la vida cotidiana que explica esto de manera perfecta:
Cuando estás esperando el ascensor y apretás el botón, ¿qué pasa si lo apretás de nuevo? Nada. El ascensor ya fue llamado. La segunda vez que apretás el botón, el sistema lo ignora porque el efecto ya fue producido. No importa cuántas veces lo toques el resultado siempre es el mismo.
Eso es la idempotencia. Una operación es idempotente cuando repetirla no cambia nada. El estado del sistema después de la segunda llamada es idéntico al estado después de la primera.
¿Por qué los reintentos son inevitables?
Imaginá que estás comprando entradas para un recital. Apretás “Confirmar compra”, la pantalla se queda girando y después de 10 segundos te aparece un error genérico. ¿Se procesó el pago o no? No tenés idea. Lo único que podés hacer es intentarlo de nuevo y esperar que esta vez funcione.
Eso mismo pasa en el mundo real todo el tiempo: la conexión se cae antes de que llegue la respuesta, el servidor tarda demasiado y el cliente hace timeout, la app se cierra en el momento equivocado, o simplemente el usuario se desespera y aprieta el botón dos veces.
En todos esos casos el cliente no sabe si el servidor llegó a procesar el request o no. Su única opción razonable es reintentar. Y si tu sistema no está preparado para eso, el resultado son pedidos duplicados, cobros dobles, o usuarios registrados dos veces.
Los reintentos no son un bug del cliente. Son una respuesta lógica ante la incertidumbre de las redes distribuidas. El servidor tiene que estar diseñado para recibirlos.
Operaciones que ya son idempotentes
Antes que nada vale la pena entender qué operaciones HTTP son naturalmente idempotentes:
- GET: Siempre idempotente. Pedís datos, los obtenés. Pedirlos de nuevo no cambia nada (asumiendo que no hubo cambios en la información que estás solicitando mientras ejecutás las peticiones).
- PUT: Idempotente por diseño.
PUT /users/1con el mismo body siempre deja al usuario en el mismo estado. - DELETE: Borrar algo que ya fue borrado debería simplemente no hacer nada (o devolver 404).
La mayoría de las operaciones críticas de un sistema (crear un pago, registrar un usuario, emitir una factura, etc) son POST y ninguna de ellas es idempotente de forma natural. Hay que hacerlas idempotentes explícitamente.
¿Cómo se implementa en la práctica?
APIs REST
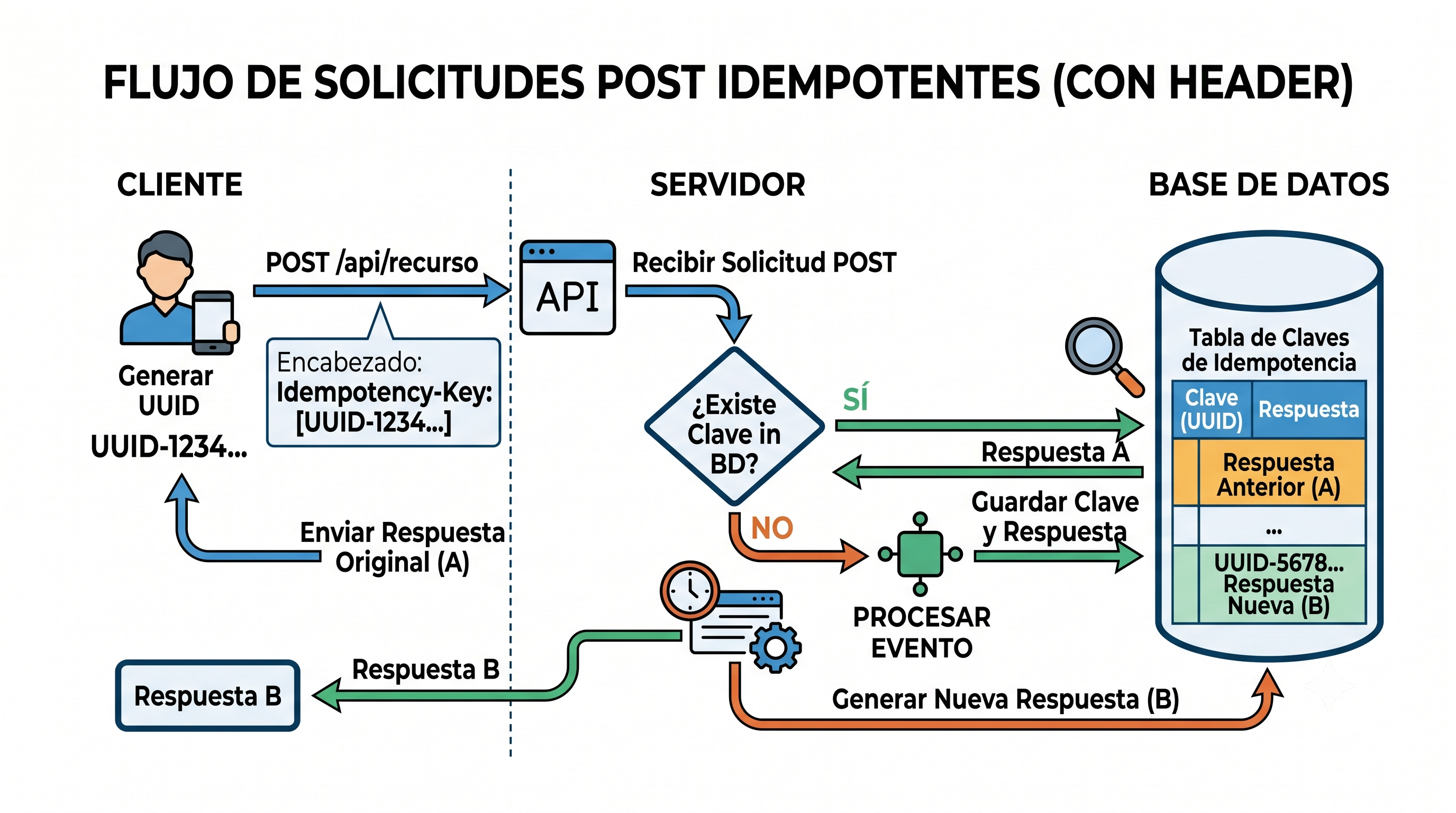
Como mencionamos antes, POST no es idempotente por naturaleza, pero podemos lograrlo con un pequeño contrato entre cliente y servidor. La idea es pedirle al cliente que incluya un header (convencionalmente llamado Idempotency-Key) con un valor único por operación, típicamente un UUID que genera del lado del cliente antes de mandar el request.
Del lado del servidor, la lógica es simple: cuando llega el request, buscamos esa key en la base de datos. Si ya existe, devolvemos exactamente la misma respuesta que devolvimos la primera vez. Si no existe, procesamos la operación normalmente, guardamos el resultado y registramos la key para futuras verificaciones.
El cliente puede reintentar las veces que quiera. El proceso de la información siempre ocurre una sola vez.
Código de ejemplo
Veamos cómo se vería esto en un handler de Go. El flujo es simple: si la key ya existe devolvemos el resultado guardado, si no existe procesamos y guardamos. Dos caminos, una sola línea de lógica de negocio.
func HandlePayment(w http.ResponseWriter, r *http.Request) {
// Cada request debe incluir una Idempotency-Key en el header.
// Esta key puede ser un UUID generado por el cliente que identifica la operación.
key := r.Header.Get("Idempotency-Key")
if key == "" {
http.Error(w, "Idempotency-Key requerida", http.StatusBadRequest)
return
}
// Buscamos la key en el store. En Go, las funciones devuelven el error
// como valor de retorno: err == nil significa que la operación fue exitosa
// (la key existe). Si es así, ya procesamos este request antes y devolvemos
// el resultado guardado directamente sin volver a procesar nada.
cached, err := store.Get(ctx, key)
if err == nil {
writeJSON(w, http.StatusOK, cached)
return
}
// La key no existe: es la primera vez que vemos este request.
// Procesamos la operación normalmente.
result := processPayment(r)
// Guardamos el resultado asociado a la key antes de responder.
// Así, si el cliente reintenta con la misma key, devolvemos
// este resultado sin ejecutar processPayment() de nuevo.
store.Set(ctx, key, result, 24*time.Hour)
writeJSON(w, http.StatusCreated, result)
}
Colas de mensajería
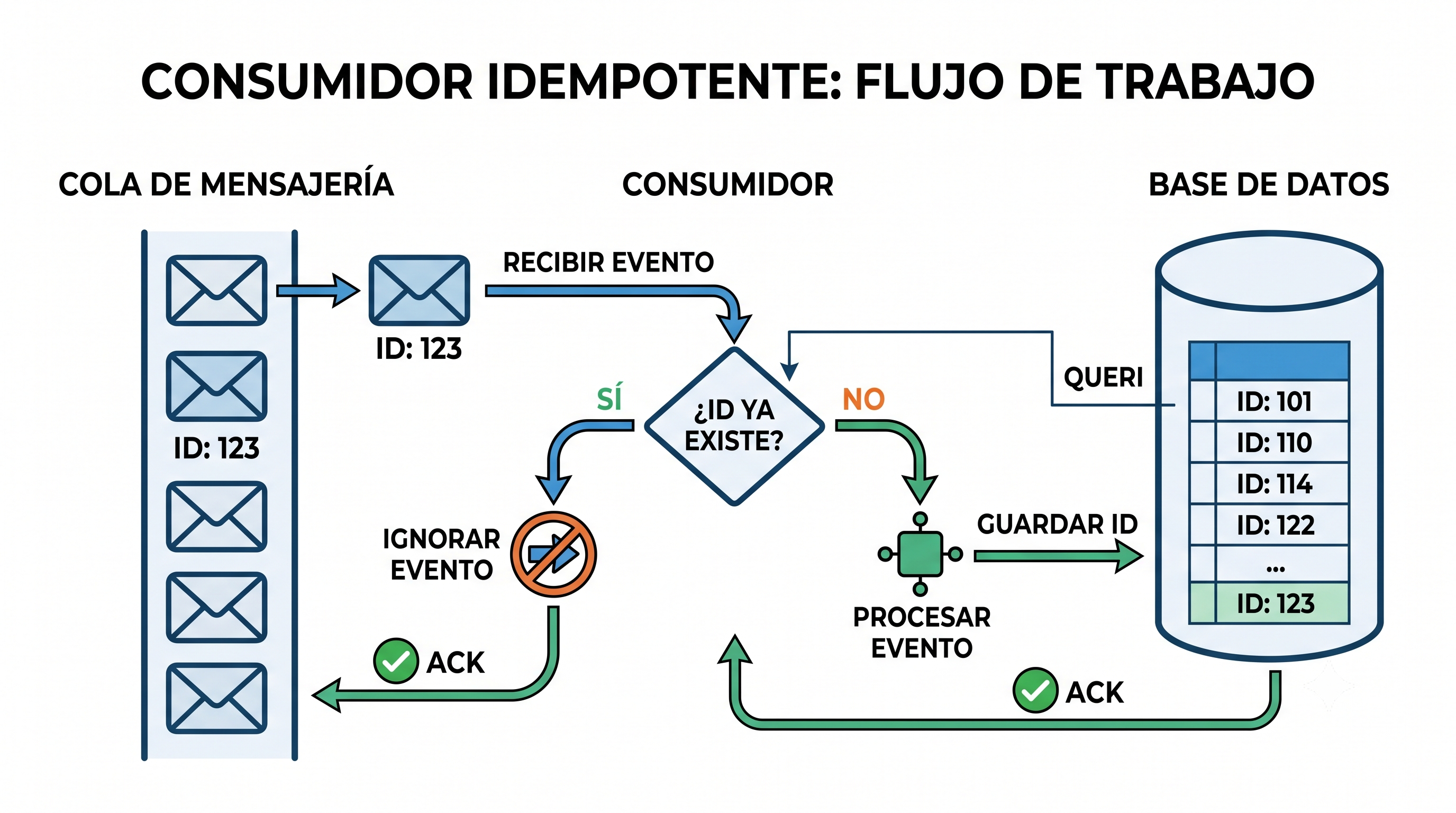
El mismo principio aplica cuando consumís eventos de una cola como SQS o RabbitMQ. En la entrega at-least-once, un mensaje puede llegar más de una vez si el broker no recibió confirmación a tiempo. Para manejarlo, al recibir un evento tomamos su ID de transacción y lo buscamos en la base de datos.
Si ya existe, le damos ACK a la cola pero ignoramos el evento (ya fue procesado). Si no existe, procesamos el evento, guardamos el ID y recién entonces damos el ACK. El resultado hacia la cola es siempre el mismo (un ACK), pero internamente nos aseguramos de que el efecto ocurra una sola vez.
Código de ejemplo
En RabbitMQ, cada mensaje trae un MessageId que podemos usar como key de idempotencia. El flujo es el mismo que en la API REST: si el ID ya existe en el store, el evento fue procesado antes y lo ignoramos. Si no existe, lo procesamos y guardamos el ID. La diferencia está en que acá la “respuesta” no es un JSON sino un ACK a la cola.
func HandleEvent(msg amqp.Delivery) {
// Cada mensaje trae un ID único que identifica la transacción.
// Lo usamos como key para detectar duplicados.
eventID := msg.MessageId
if eventID == "" {
msg.Nack(false, false)
return
}
// Buscamos el ID en el store. El _ descarta el valor devuelto porque
// solo nos importa saber si la key existe, no su contenido.
// Si err == nil (la key existe), el evento ya fue procesado: ACK y listo.
_, err := store.Get(ctx, eventID)
if err == nil {
msg.Ack(false)
return
}
// El ID no existe: es la primera vez que vemos este evento.
// Procesamos el mensaje normalmente.
processEvent(msg.Body)
// Guardamos el ID antes de dar el ACK para evitar reprocesar
// si el broker reenvía el mensaje por no recibir confirmación a tiempo.
store.Set(ctx, eventID, "processed", 24*time.Hour)
msg.Ack(false)
}
Usos comunes en IT
La idempotencia aparece constantemente en sistemas reales. Estos son algunos de los contextos donde más se aplica:
- Medios de pago: Cualquier API de cobro necesita garantizar que un pago se procese exactamente una vez. Un reintento por timeout no puede terminar en dos cargos al usuario.
- Envío de emails y notificaciones push: Si un worker falla después de enviar pero antes de confirmar el procesamiento, el sistema puede reenviar el evento. Sin idempotencia, el usuario recibe dos emails de confirmación o dos notificaciones.
- Webhooks: Cuando un servicio externo manda un webhook, espera un 200 como confirmación. Si no lo recibe a tiempo, reintentará. Los endpoints tienen que estar preparados para recibir el mismo evento más de una vez.
Beneficios de implementarla
Diseñar sistemas con idempotencia tiene consecuencias concretas que van más allá de “evitar duplicados”:
- Los reintentos se vuelven seguros: El cliente puede reintentar un request sin miedo a efectos secundarios. Esto simplifica enormemente el manejo de errores del lado del cliente, que en lugar de intentar adivinar si el servidor procesó o no la operación, simplemente puede volver a intentar.
- El sistema es resiliente ante fallos de red: Un timeout deja de ser un problema crítico. Si la respuesta nunca llegó, el cliente reintenta y el servidor devuelve el mismo resultado sin reprocesar nada.
- Mejor experiencia de usuario: El usuario nunca ve un cobro duplicado, un pedido repetido o un email de más. El sistema absorbe la incertidumbre de la red sin trasladarla al usuario.
- Trazabilidad natural: Cada operación queda registrada con su key única. Eso actúa como un audit trail implícito. Se puede saber exactamente cuántas veces llegó un request y cuándo fue procesado por primera vez.
Detalles que importan en producción
La implementación básica es sencilla, pero hay algunos edge cases que vale considerar antes de llevar esto a un sistema real.
- ¿Qué pasa si llega la misma key con un body diferente? No hay una única respuesta correcta: podés ignorar el segundo request y devolver el resultado original, devolver un error, o loguear la inconsistencia para investigarla. La convención más adoptada es devolver un
409 Conflict, que le indica al cliente que algo está mal de su lado y que el request no va a ser procesado. - ¿Cuánto tiempo se guarda la key? Depende del dominio: pueden ser minutos, horas o días. La pregunta que vale hacerse es: ¿a partir de cuándo un reintento deja de ser un reintento y pasa a ser una operación nueva?
- ¿Qué pasa si dos requests con la misma key llegan exactamente al mismo tiempo? La solución es una escritura atómica: en lugar de verificar si la key existe y después guardarla (dos operaciones separadas donde se pueden generar race conditions), se intenta escribir directamente usando una operación que la base de datos o el store garantiza como indivisible. Si se tiene éxito, este request procesa la operación. Si falla porque la key ya existe, significa que otro request llegó primero y se devuelve el resultado que ese primer request ya guardó. Sin bloqueos, sin esperas.
Conclusión
La idempotencia no es un detalle de implementación, es una decisión de diseño. Y como la mayoría de las buenas decisiones de diseño, es invisible cuando está bien hecha: el usuario aprieta “Confirmar” dos veces y simplemente funciona.
La próxima vez que diseñes un endpoint POST, la pregunta que vale la pena hacerse antes de escribir la primera línea es: ¿qué pasa si el mismo request llega dos veces? Hacerse esa pregunta en el momento de diseño cuesta mucho menos que responderla en producción.
Gracias por leer, nos vemos en la próxima entrega 👋